這篇文章講統計學中的一些常用指標。
以數值指標來描述資料
- 連續型變數的四個特性:
- 集中趨勢(Central Tendency)
- 分散或變異趨勢(Dispersion or Variability)
- 偏態(Skewness)
- 峰度(Kurtosis)
集中趨勢
- 資料有往中央位置靠近的趨勢。
- 指標:
- 平均數(mean)
- 中位數(median)
- 眾數(mode)
平均數
- 群體平均數:μ=NΣXi,N 為群體大小
- 樣本平均數:X=nΣXi,n 為樣本大小
中位數
- 群體中位數:η
- 樣本中位數:x~
眾數
指標使用指南
- 平均數對離群值非常敏感,而中位數和眾數不敏感。因此當資料中有離群值的時候,使用中位數或眾數,否則,使用平均數。
分散或變異趨勢
- 一組資料差異大小或數值變化的一個量數。
- 指標:
- 全距(Range)
- 變異數(Variance)
- 標準差(Standard Deviation)
- 變異係數(CV)
全距
- R = Max - Min
- 缺點:當一組數據中有離群值出現或資料筆數太多(n > 10)時,全距並非一個很好的衡量資料分散程度的量數。
變異數和標準差
- 群體變異數:σ2=NΣi=1N(Xi−μ)2
- 樣本變異數:S2=(n−1)Σi=1n(Xi−x)2=(n−1)Σi=1nXi2−n(ΣXi)2
- 群體標準差:σ=σ2
- 估計值:4Rpopulation
- 樣本標準差:S=S2
- 估計值:4Rsample
變異係數
- 標準差和變異數是衡量一組數據絕對變異(absolute vatiation)的指標,即此指標之大小與數據的單位尺度有關係,因此,若要比較數組單位尺度不同的數據時,需使用一個衡量相對變異的指標,即變異係數。
- 群體相對變異:CV=μσ×100%
- 樣本相對變異:CV=xS×100%
偏態
說明一組數據分佈的形狀。
單峰分佈的三種型態:
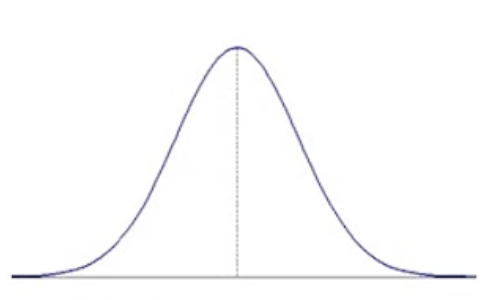
- 對稱:平均數 = 中位數
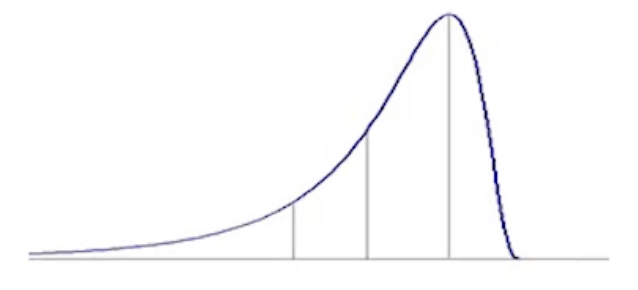
- 左偏:平均數 << 中位數
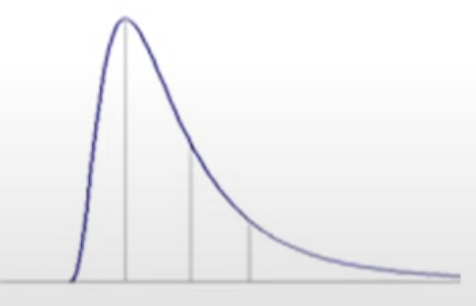
- 右偏:平均數 >> 中位數
偏態係數
樣本偏態係數:
g1=S3n−1Σi=1n(Xi−X)3
- g1=0:對稱
- g1>0:右偏
- g1<0:左偏
峰度
峰度係數
樣本峰度係數:
g2=S4n−1Σi=1n(Xi−X)4−3
- g2=0:常態峰
- g2>0:高狹峰
- g2<0:低闊峰
非中趨勢指標
- 百分位數
- 四分位數(Q1−Q3, 25% - 75%)
- Q1=0.25(n+1)
- Q3=0.75(n+1)
- 中四分位距:
- IQR=Q3−Q1
- 避免極端值或離群值的干擾
數據之應用
經驗法則
如果資料呈常態分佈,則有:
- 68.26% 的數據在 μ±σ 範圍內
- 95.44% 的數據在 μ±2σ 範圍內
- 99.73% 的數據在 μ±3σ 範圍內
離群值:當值沒有落在 μ±3σ 範圍內,即為離群值。
柴比雪夫定理
不論連續型數據呈現什麼樣的分布狀態,至少有 (1−K21)×100% 的數據會落在 μ±Kσ 範圍內。
- 至少有 0% 的數據在 μ±1σ 範圍內。(令 K=1)
- 至少有 55.56% 的數據在 μ±1.5σ 範圍內。(令 K=1.5)
- 至少有 75% 的數據在 μ±2σ 範圍內。(令 K=2)
- 至少有 88.88% 的數據在 μ±3σ 範圍內。(令 K=3)
- 至少有 93.75% 的數據在 μ±4σ 範圍內。(令 K=4)
- 至少有 96% 的數據在 μ±5σ 範圍內。(令 K=5)
盒鬚圖
同時展示出集中趨勢、離中趨勢、偏態、最小值、最大值等。
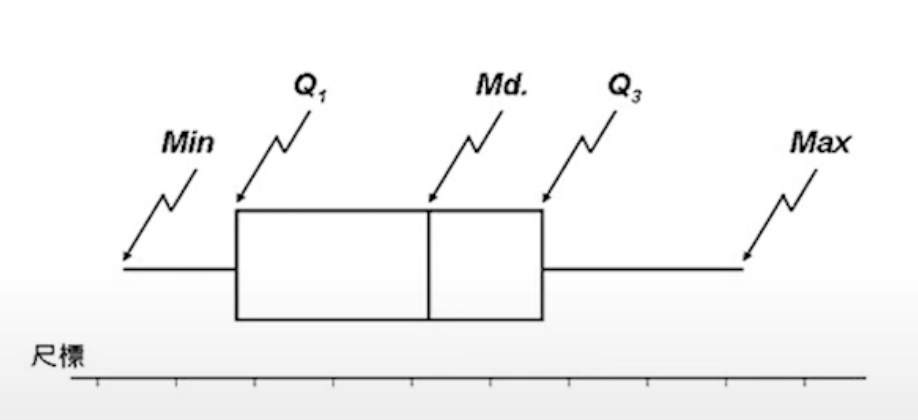
- 超過盒鬚圖之盒 1.5(Q3−Q1) 至 3(Q3−Q1) 距離內之值可當作離群值
- 超過盒鬚圖之盒 3(Q3−Q1) 距離外之值可當作非常可能之離群值
Z分數
Z-score 是一個標準化數值,代表原始數據(Xi)偏離其平均數(μ)Z 個標準差。
-
Zi=σxi−μ
-
Zi>0:原始數據 > 平均數
-
Zi<0:原始數據 < 平均數
-
Zi=0:原始數據 = 平均數
加權平均
- 群體加權平均:μW=ΣWiΣWiXi,i=1,…,N
- 樣本加權平均:XW=ΣWiΣWiXi,i=1,…,n
統計學(2)
https://blog.kynix.tw/posts/1731069925249/
姓名標示-非商業性-相同方式分享 4.0 國際