這篇文章介紹常用之連續型機率分佈。在醫學領域,基本只需要理解幾個比較重要的機率分佈模式即可,或許常態分佈理解就夠了,其他的了解即可。
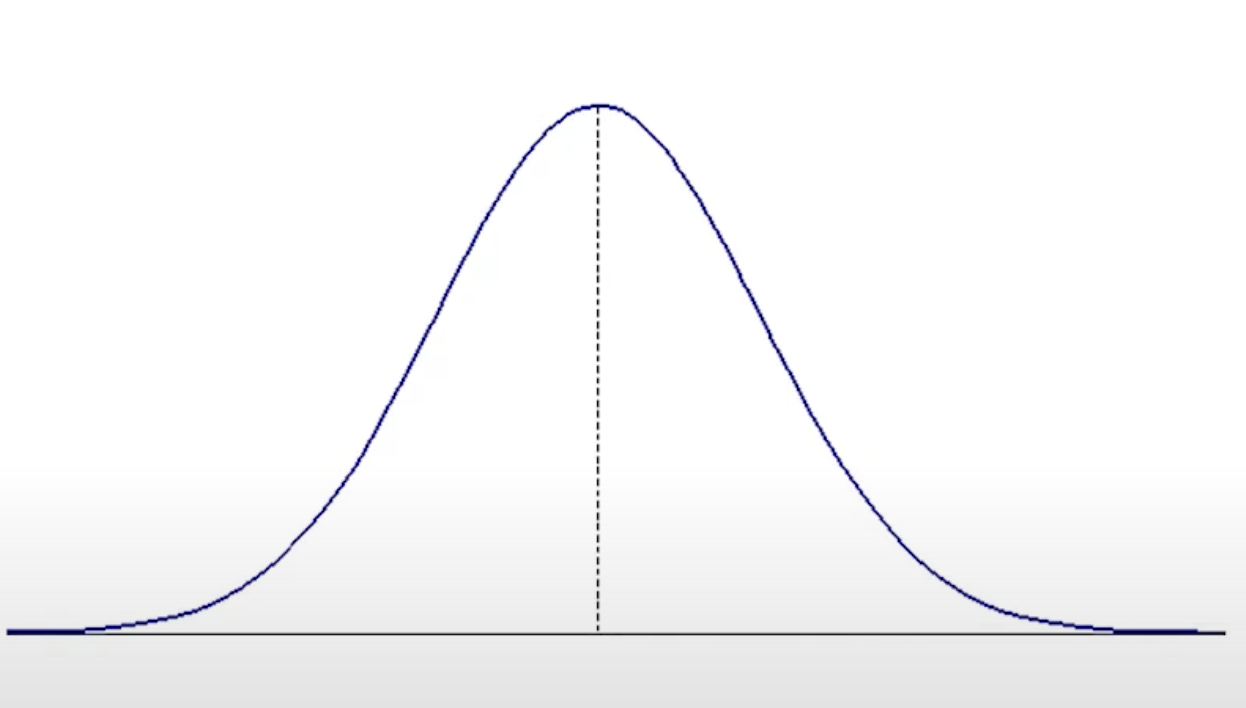
常態分佈
機率密度函式:
f(x)=2πσ1e−(x−μ)2/2σ2,−∞<x<+∞
常以 N(μ,σ) 或者 N(μ,σ2) 表示。
- μ:影響圖像中心的位置。μ 越大,曲線中心右移。
- σ:影響圖像的形狀。σ 越大,曲線越矮胖。
特性:
- 圖像對稱於 μ
- 隨機變數x的值可由 −∞ 至 +∞
- 鍾形分佈
- 曲線下面積為 1
- 集中趨勢量數(平均數、中位數、眾數相同)
標準常態分佈
N(0,1) 為標準常態分佈,使用字母 Z 表示。因此標準常態分佈又可以稱為 Z 分佈。
一般常態分佈之標準化:
Z=σX−μ,Z∼N(0,1)
常態分佈的判斷
- 直方圖:只要出現鐘形分佈圖形,即判定數據呈常態分佈。
- 常態機率圖:只要圖形接近直線,即判定數據呈常態分佈。
- 統計假設檢定:只要以下統計檢定之顯著度 p−value>0.05,即判定數據呈常態分佈。
使用常態機率估算二項機率
當 n 很大,p 接近 0.5 時,可以使用常態機率來估算二項機率。
例8:擲一個銅板 100 次,試求以下機率:
- 至少看到 70 次正面(人頭)?
- 看到正好 50 次正面?
首先做連續性校正。其含義是:如果一個離散型隨機變數 X,有 P(a≤X≤b),則將其 pass 為:P(a−21≤X≤b+21)
則上述問題轉化為:
- P(X≥69.5),或 P(Z=σX−μ≥3.9)
- P(49.5≤X≤50.5),或 P(−0.1≤Z=σX−μ≤0.1)
轉化爲 μ=np,σ=npq 之常態分佈。
則 μ=50,σ=5,則有 X∼N(50,5)。
查表得:
- P(X≥70)≈0.005%
- P(X=50)≈7.96%
對數常態分佈
當變數X之自然對數 lnX 呈常態分佈,則 X 服從對數常態分佈。
機率密度函數:f(x)=⎩⎨⎧2πβ1x−1e2β2(lnx−α)2,x>0,β>00,otherwise
期望值和變異數:
- 期望值:Exp(X)=μ=eα+21β2
- 變異數:Var(X)=σ2=e2α+β2(eβ2−1)
齊一分佈(均等分佈)
連續型隨機變數 X 為齊一隨機變數,則 X 在某一連續的區間上有相同的機率密度。X 之機率密度函數如下:
f(x)={β−α1,α<X<β0,otherwise
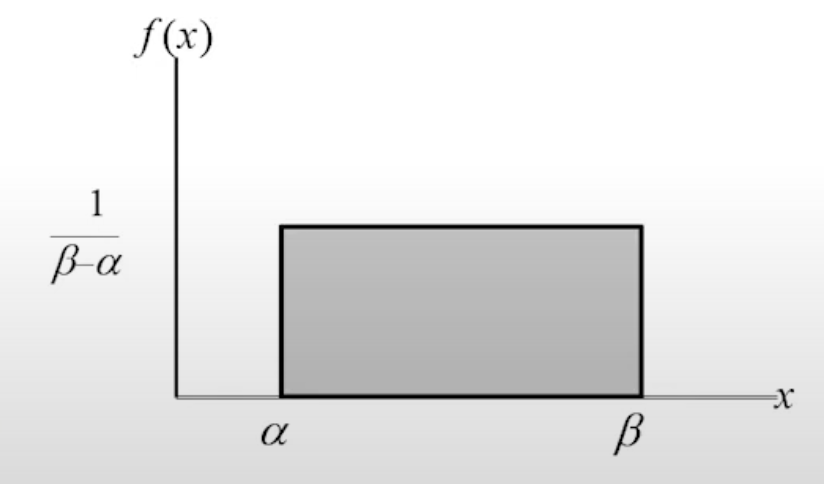
期望值:
Exp(X)=μ=2α+β
變異數:
Var(X)=σ2=12(β−α)2
指數分佈
機率密度函數:
f(x)={λe−λx,x>0,λ>00,otherwise
期望值:
Exp(X)=λ1
變異數:
Var(X)=λ21
累加函數:
FX(t)=P(X≤t)=∫0tλe−λxdx=1−e−λt
則 P(X>t)=e−λt
在波瓦松過程中,兩連續事件間的等候時間呈現指數分佈。
伽馬分佈
機率密度函數:
f(x)={βαΓ(α)1xα−1e−βx,x>0,α>0,β>00,otherwise
其中 Γ(x) 爲伽馬函數:Γ(x)=∫0∞xα−1e−xdx,α>0
伽馬函數的特性:
- Γ(α)<∞,if α>0
- Γ(α)=(α−1)Γ(α−1),if α>1
- Γ(α)=(α−1)!,當 α 爲一正整數
期望值與變異數:
Exp(X)=αβ
變異數:
Var(X)=αβ2
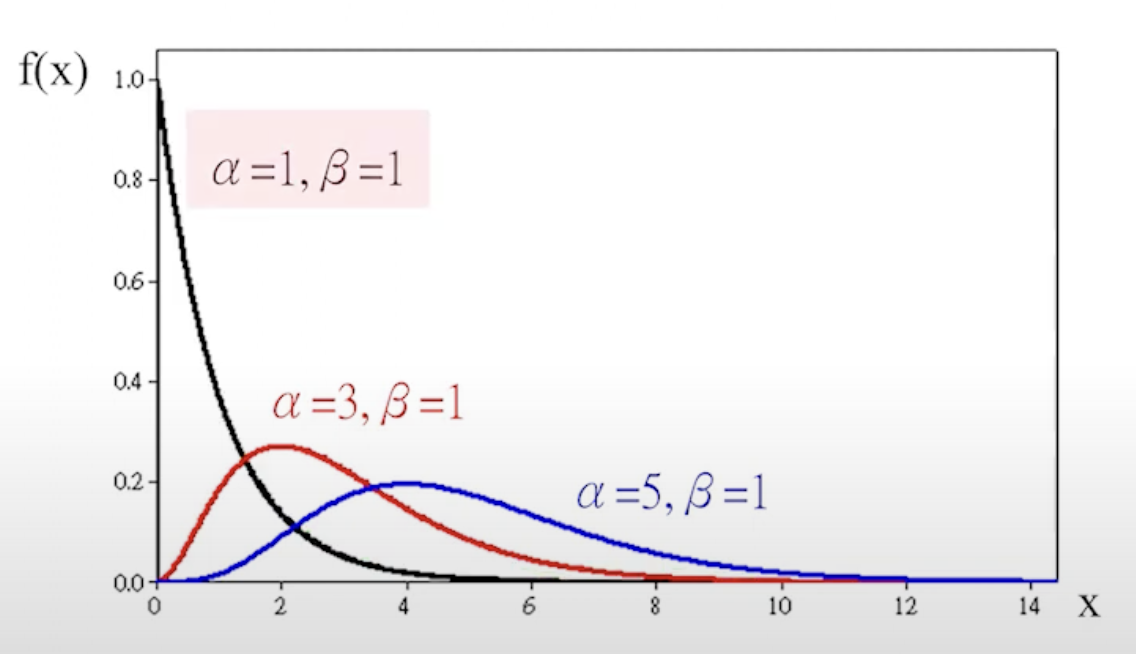
韋伯分佈
機率密度函數:
f(x)=αβ(βx)α−1e−βxα,x>0
α>0,β>0,α 爲形狀參數,β 爲尺度參數。
當 α=1,韋伯分佈是指數分佈(λ=β1),α=2 時,韋伯分佈是瑞利分佈。
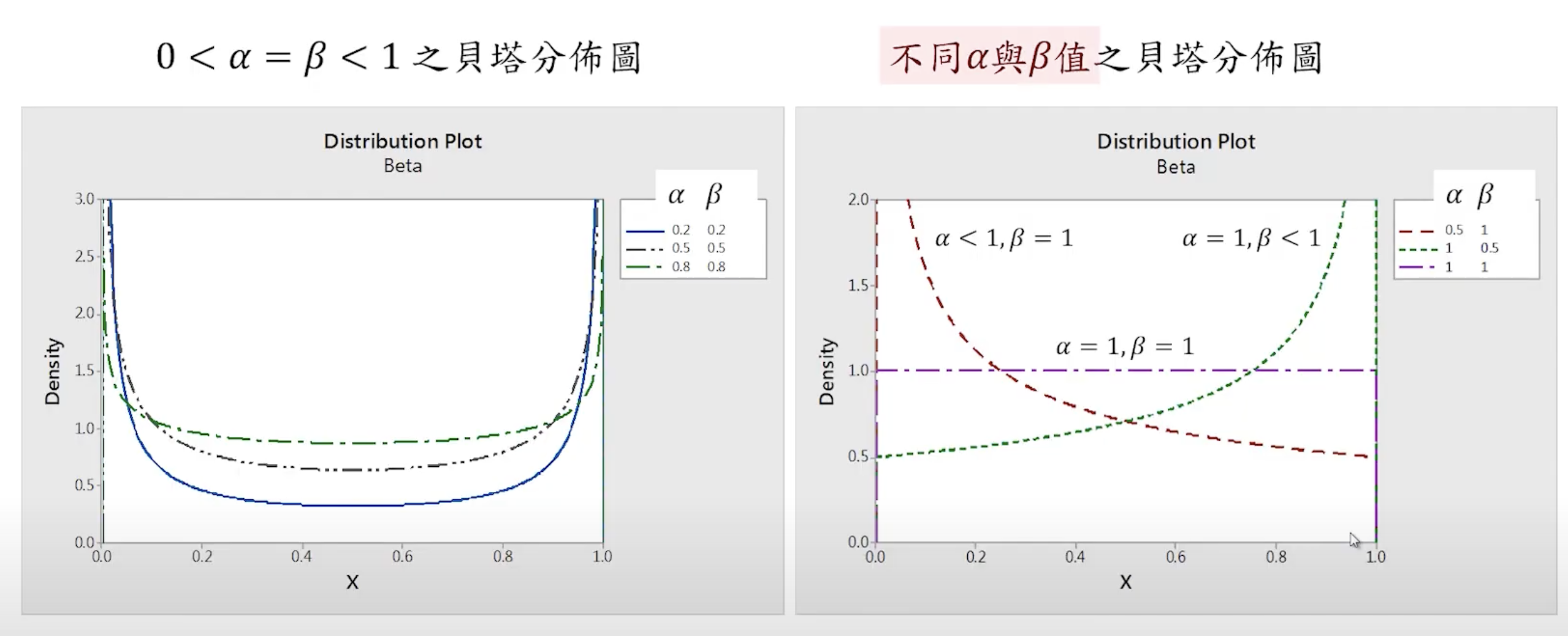
貝塔分佈
機率密度函數:
f(x;α;β)=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1,0<x<1,α,β>0