推理統計實際上是群體的參數未知,使用樣本統計量來推理群體參數的方法。推理統計分為估計和檢定。
這篇文章介紹估計。估計分為點估計和區間估計。
點估計
定義:一個群體參數之點估計式或估計量(estimator)是一個法則(rule)或公式(formula),利用此法則或公式可以由樣本資料中計算出一個單一數值(single number)以估計群體參數。由點估計式所得之單一數值稱為該參數之估計值(estimate)。
例如,μ 的估計值是 X,σ 的估計值是 s,P 的估計值是 p^。
區間估計
定義:一個群體參數之區間估計式(interval estimator)是一個法則(rule),利用此法則可以由樣本資料中計算出兩個數字(two numbers)或一個區間之上、下限以估計群體參數,並指出該區間包含群體參數的機率。
信賴係數:信賴係數(或信賴度)是指區間估計式之上下限,包含群體參數之機率或信心。
信賴區間的意義:我們有 (1−α)100% 的信心認為統計量會落在計算出的區間內。
μ 的區間估計
大樣本(large sample)
根據中央極限定理,X 服從常態分配:X∼N(μ,σ/n)。
(1−α)100% 的信賴區間:X±Z21−αnσ(σ 已知)、X±t2α,n−1ns≈X±Z21−αns(σ 未知)
1−α 稱信賴係數;(1−α)×100% 稱信賴水準。一般使用 95%。
小樣本(small sample)
前提:群體假定接近常態分配。
(1−α)100% 的信賴區間:X±t2α,n−1ns
P 的區間估計
適用於大樣本(np^≥4&&nq^≥4)的 (1−α)×100% 信賴區間:p^±Z2αnp^q^
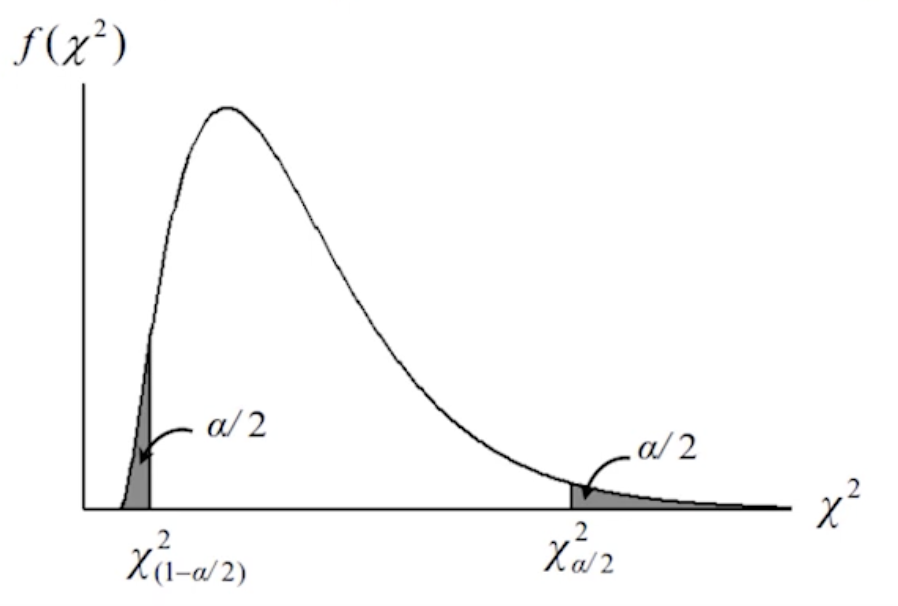
σ2 的區間估計
前提:假定群體服從近似常態分佈。
(1−α)100% 信賴區間:χ2α2(n−1)s2≤σ2≤χ1−2α2(n−1)s2
選擇樣本數以估計群體參數值
μ 的選擇
我們期望:得到一個樣本數量 n,使得 μ 的估計值同真實值的誤差不超過E個單位的機率為 (1−α):
n=[EZ(1−α)/2σ]2
如果 σ2 未知,則使用 s2 代替。
P 的選擇
我們期望:得到一個樣本數量 n,使得 P 的估計值同真實值的誤差不超過 E 個單位的機率為 (1−α):
n=pq[EZ(1−α)/2]2
此公式中的 p 和 q 可以使用過去資料來估計。
兩個群體參數差異之區間估計
獨立樣本的平均數差異(μ1−μ2)區間估計
大樣本:(X1−X2)±Z21−αn1σ12+n2σ22,如果 σ1 和 σ2 未知,使用 s 代替(t 分佈和 z 分佈接近)。
- 如果 LCL>0,UCL>0,群體參數 θ1>θ2
- 如果 LCL<0,UCL<0,群體參數 θ1<θ2
- 如果 LCL<0,UCL>0,群體參數 θ1和θ2沒有辦法推論是有差異的。(注意!不是沒有差異,是沒有辦法證明有差異)
小樣本,σ1 和 σ2 均未知,但假定 σ1=σ2=σ=sp=n1+n2−2(n1−1)s12+(n2−1)s22=n1+n2−2Σi=1n(x1i−X1)2+Σi=1n(x2i−X2)2,則有:(x1−x2)±tα/2sp2(n11+n21),d.f=ν=n1+n2−2
- σ 判斷方法:如果 s22s12≤3,則一般認為兩個 σ 沒有差。
小樣本:σ1 和 σ2 均未知,但 σ1=σ2,則有:(x1−x2)±tα/2n1s1+n2s2,d.f=ν=n1−1(n1s1)2+n2−1(n2s2)2(n1s12+n2s22)2
配對樣本的平均數差異(μ1−μ2)區間估計
μ1−μ2 之 (1−α)100 的信賴區間估計:
大樣本:d±Z21−α(nσd)
小樣本:d±t2α(nsd)
例:某健身中心針對欲減重者提供減肥運動計畫,並隨機抽取 12 位欲減重者參加此減肥運動計畫。兩個月後量測每位欲減重者之體重(以公斤為單位),減肥前後資料如下表所示。請找出減肥前後體重差異的 95% 信賴區間。請問減肥運動計畫是否有效?
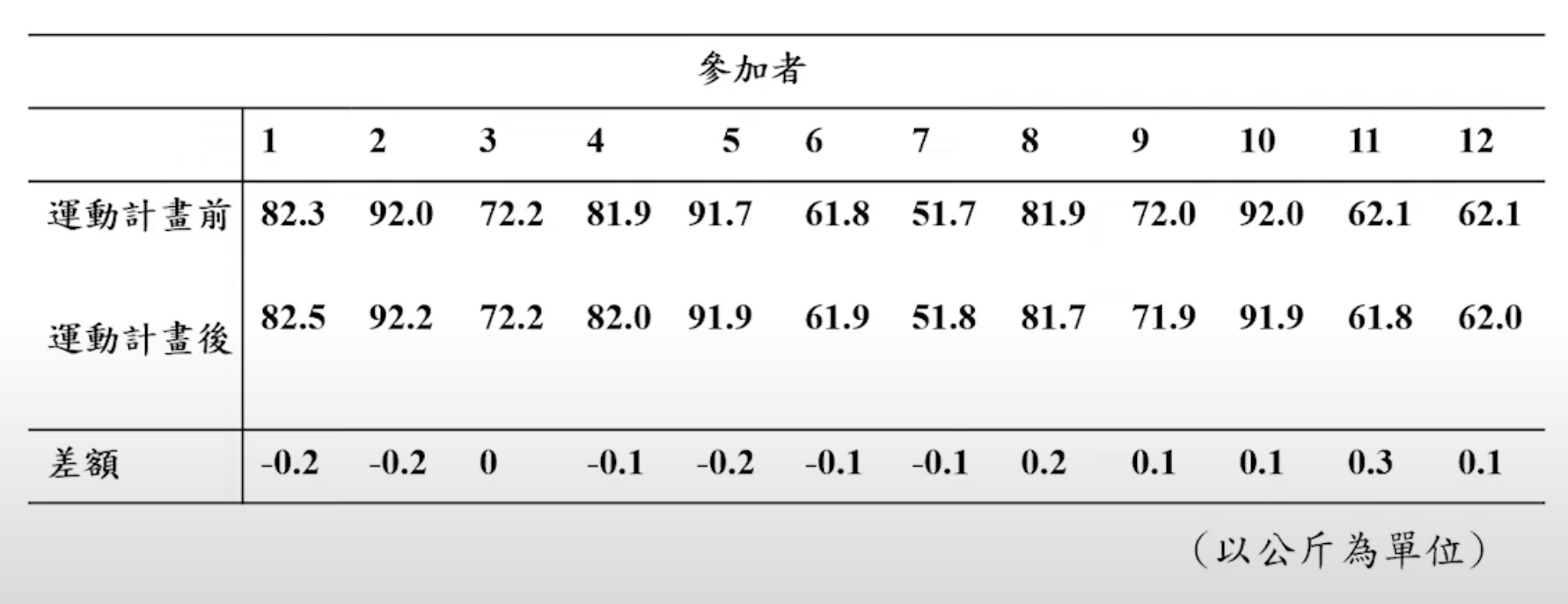
解決如下:

獨立樣本的比例差差異(P1−P2)區間估計
條件:大樣本(n1p1^≥4,n1q1^≥4,n2p2^≥4,n2q2^≥4)
(p1^−p2^)±Z21−αn1p1^q1^+n2p2^q2^
獨立樣本的變異數比的差異(σ22σ12)區間估計
s22s12Fα/2(ν1,ν2)1≤σ22σ12≤s22s12Fα/2(ν2,ν1)
選擇樣本大小(n)以估計兩群體參數差異
-
μ1−μ2:
n1=n2=[EZ(1−α)/2]2(σ12+σ22)
-
P1−P2:
n1=n2=[EZ(1−α)/2]2(p1q1+p2q2)